- Feb 27, 2024
- 4 min read
Updated: Mar 5, 2024
In this blog post, we will delve into how API integrations are transforming interactions with AI technologies in point cloud processing. We'll demonstrate how these integrations can simplify complex tasks, making them more manageable and efficient. Specifically, we'll focus on connecting to Flai via APIs, uploading datasets, using processing flows for AI classification and downloading the data.
Overview of the procedure
The entire procedure involves a series of steps:
Getting the Authentication Token: This is the first step to access the API functionalities.
Uploading data via API: This step involves transferring data using the API.
Creating template flow definition via UI: Set up the template flow using the user interface.
Running template flow with the uploaded data via API: Execute the template flow on the data you've uploaded.
Checking Flow Execution Status via API: Monitor the status of your flow execution.
Downloading the Data via API: Finally, download your data through the API.
Getting the token
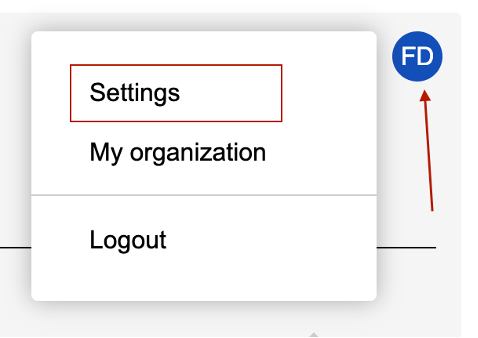
First, you will need to obtain an API token. To do this, go to your profile on app.flai.ai (indicated by the icon with your initials) and click on 'Settings'.
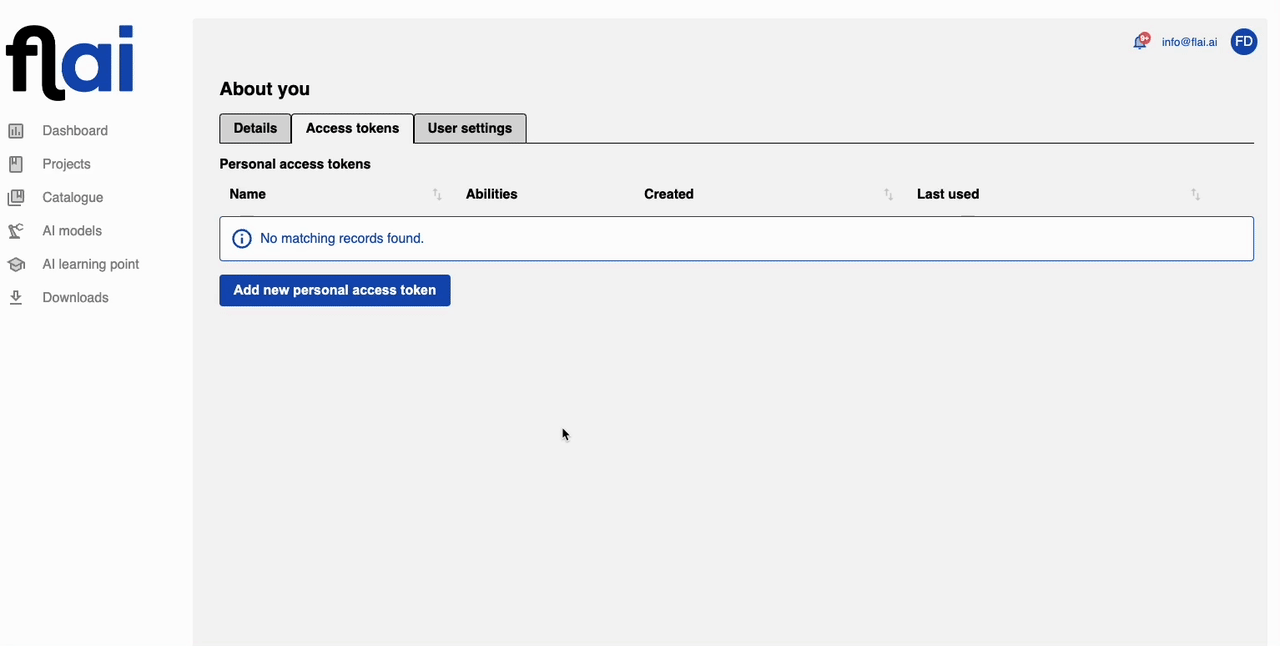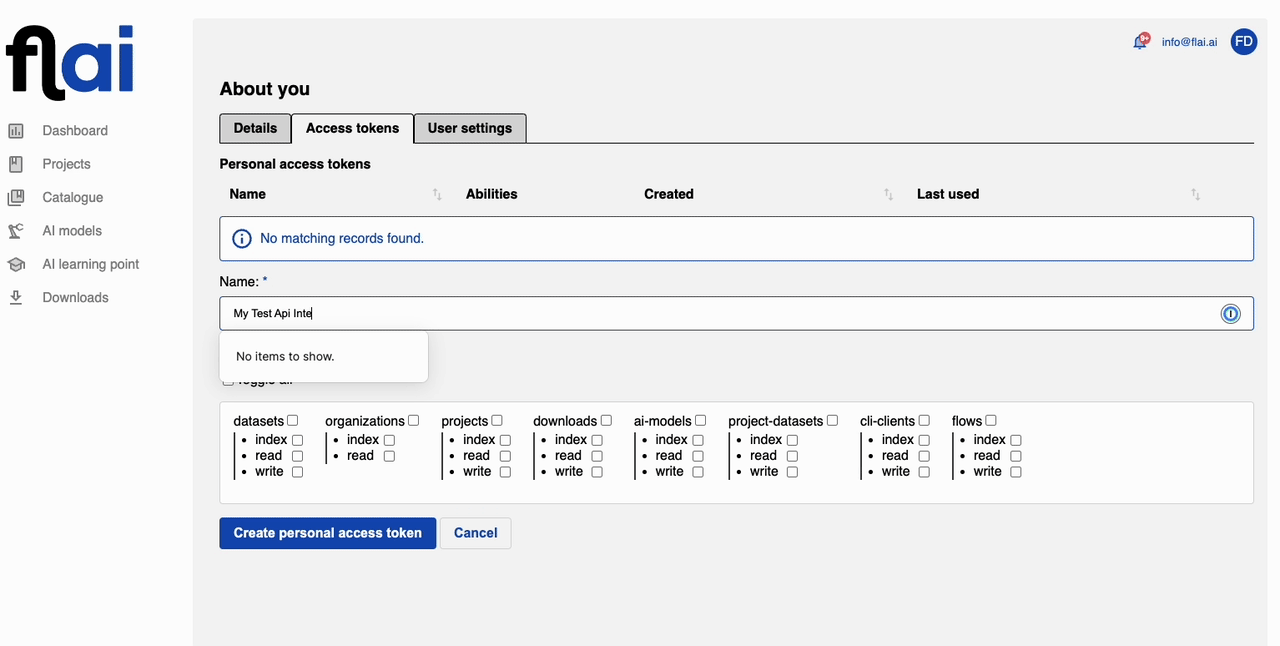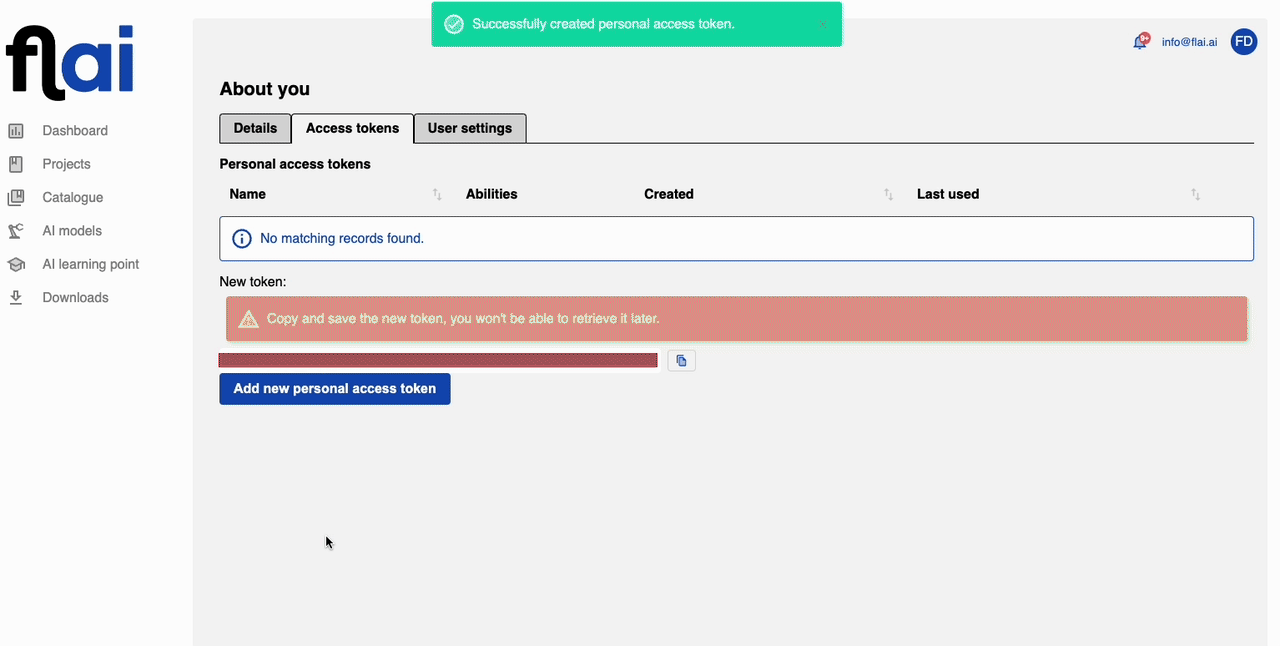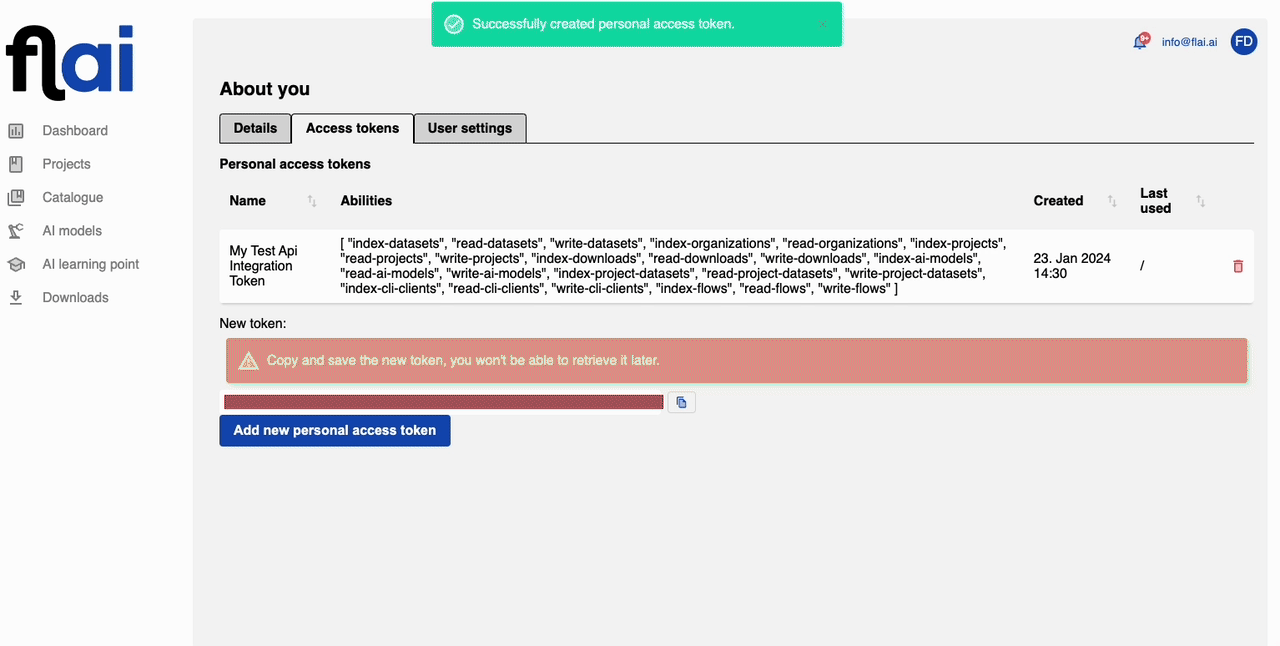
Click on 'Add new token', then enter the name for your token and select all the abilities it should have. It's possible to create multiple API tokens, each with different abilities, to suit various applications. For this tutorial, you can select all.
It's critical to keep your provided token confidential. Do not share it with anyone or post it on the internet. Possession of your token gives others API access to your account, potentially compromising its security.
For every API request you make, it's necessary to add a Bearer token to the headers. You can find more detailed information about Bearer Authentication in the provided link.
Upload the data via API
To upload data, you have three options: FTP, S3, or direct upload. In this blog, we will focus on FTP and S3 uploads.
To upload the data you need to create a `POST` request to https://api.flai.ai/api/v1/organization/{YOUR_ORGANIZATION_ID}/datasets with the following body:
{
"dataset_name": "New pointcloud from FTP",
"description": "",
"dataset_type_key": "pointcloud",
"read_write_mode": "r",
"is_public": true,
"is_annotated": true,
"srid": 3794,
"unit": "m",
"import_datasource": {
"credentials": {
"ftp_username": "my_username",
"ftp_password": "my_password",
"ftp_port": "21",
"ftp_secure": false
},
"datasource_type": "ftp",
"datasource_address": "my-ftp-server.com",
"ftp_datasource_address": "my-ftp-server.com",
"path": "/test-dataset"
}
}
You can find more info in the API documentation.
Create template flow definition via UI.
In Flai, all processing steps are organized into what are known as 'processing flows'. While it's possible to create an entire flow using the API, it's generally simpler to do so through the user interface. Additionally, you'll often find that you need to run a similar flow repeatedly. In such cases, it's practical to create a template flow. Once this template is in place, you can conveniently modify values through API calls, tailoring each execution to your specific needs.
All necessary IDs and keys required to generate the request are available in the Flow Builder, as illustrated in the image above.
Run template flow over the uploaded data via API
Now we're ready to begin processing our datasets through the API. To do this, create a POST request to https://api.flai.ai/api/v1/organization/{YOUR_ORGANIZATION_ID}/flow-template-execution . Below is an example of how to structure this request payload.
{
"flow_id": "f8bc44aa-cfac-4461-948c-e2975e747a22",
"flow_node_options": {
"point_cloud_reader_1": {
"dataset_id": "782130b6-e4d6-427d-a531-50456a18f92f"
},
"remap_classification_labels_1": {
"label_remap_schema": "3=[4, 5, 6], 2=[7]"
},
"flainet_aerial_mapping": {
"ai_model_id": "cf8f7d04-3897-46cc-ad4d-d4946e01576c",
"selected_semantic_classes": ["1", "2", "3", "16"]
},
"point_cloud_writer_1": {
"dataset_name": "Writer 1"
},
"point_cloud_writer_2": {
"dataset_name": "Writer 2"
}
}
}
To learn about the available key options, please refer to the previous section titled Create Template Flow Definition via UI.
This action will place your processing in the queue. Processing duration can vary, depending on the size of your data and the current availability of GPUs. You can monitor the status of your processing with the following API call.
Additionally, our Batch Processing feature (available in the Professional Bundle) allows you to read and write directly to your storage solutions, such as S3 or FTP.
Check flow execution status via API
To obtain the status, we need to send a GET request to https://api.flai.ai/api/v1/organization/{YOUR_ORGANIZATION_ID}/flow-executions/{FLOW_EXECUTION_ID}.
The flow execution ID can be retrieved from the response received when initiating flow template executions.
In the returned response, you will find a status indicator. Once the flow is complete, the status will change to finish. It's important to note that the response also includes information about the output datasets. We will utilize this information in the next section to download the dataset.
{
"id": "df7d6f87-2f00-4e66-9dbd-5636ef486a0e",
"created_by": "84ffb8cc-acb7-4904-aa7a-0b27b28e1005",
"updated_by": null,
"flow_id": "996b9315-8b28-485c-bbd1-e6c8853069bb",
"status": "processing",
"created_at": "2023-11-19 12:39:30",
"started_at": "2023-11-19 12:39:30",
"finished_at": null,
"total_execution_time": null,
"log_query_id": null,
"stopped_at": null,
"output_datasets": [
{
"id": "6eea1bff-e58b-40b5-8bdb-e0c9aa3fc16e",
"flow_id": "996b9315-8b28-485c-bbd1-e6c8853069bb",
"flow_execution_id": "df7d6f87-2f00-4e66-9dbd-5636ef486a0e",
"dataset_id": "444b5dd5-6d98-443f-b378-e16cadf8c863",
"is_output": true,
"created_at": "2023-11-19 12:39:30",
"dataset_name": "Writer 1",
"dataset_status": "created",
"dataset_data_size_in_gb": "0"
}
]
}
Download the data via API
To download the files, we must first request the generation of downloadable files. After this, we need to regularly check to see when the downloads are ready. Given that the dataset can become quite large, and since we need to prepare the files for downloading, this process may take some time. Once they are prepared, we can then proceed to download them.
In cases of batch processing where an FTP or S3 writer is used, this step can be skipped, as the writer will directly write to the dedicated storage.
Through the use of Flai's API, we've seen how tasks such as uploading datasets, creating and running template flows, and downloading processed data can be streamlined, making these processes more efficient and user-friendly. This blog post has walked you through the essential steps, from obtaining an API token to executing and monitoring your data processing. As we continue to embrace these technologies, the potential for innovation in AI applications is boundless, opening new horizons for advanced data processing and analysis.
Recent Posts
How to Keep Original (Ground) Labels Unchanged When Using Flai Classification
Pushing the Boundaries of Situational Awareness at REPMUS 2025: Our AI-Driven REA Journey